
My Interpretation of the Modern Data Stack
Data Engineering Architecture:
This a post with information I have gathered and my interpretation on what I have learned and used.
Modern Data Stack:
A data stack is a collection of various technologies that allow for raw data to be processed before it can be used. A modern data stack (MDS) consists of the specific tools that are used to organize, store, and transform data.
Legacy data stack:
- Technically heavy
- Requires lots of infrastructure
- Time-consuming
Modern data stack:
- Cloud configured
- Ease of use
- Suite of tools is designed with non-technical employers in mind (Low Code / No Code)
- Saves time
Simplified Example of a Modern Data Stack.
ELT
Destination:
- Data Warehouse : Snowflake
- Data Lake: Snowflake
- Visualization: Looker
- Governance: Data Catalog & Data Governance | Alation
Simplified Example of a Modern Data Stack.
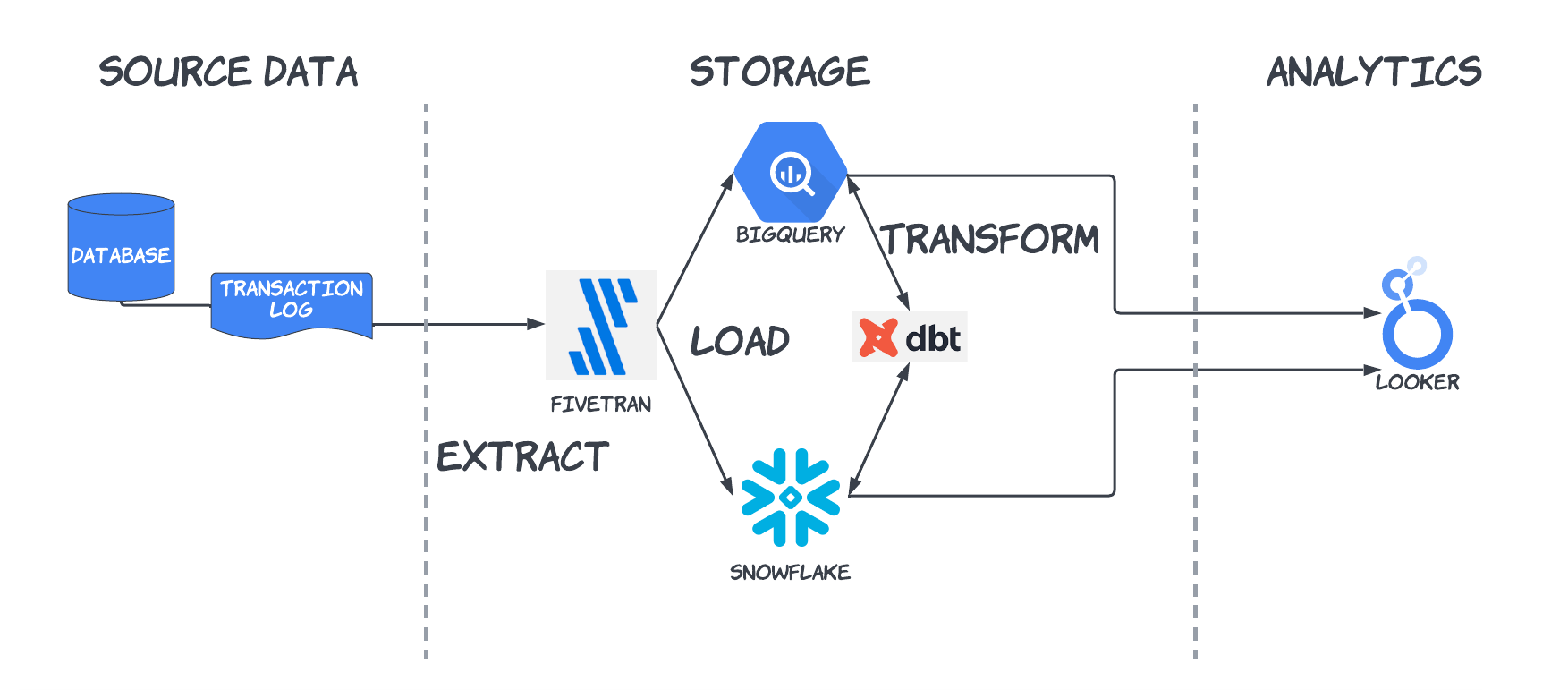
Tools typically used in my experience.
Function | Managed Services | Open Source | GCP Services |
Extract: | Fivetran or Stich | Debezium, Airbyte, Meltano or SQL script to pull to data | |
Transform: | Fivetran(limited) and or DBT Cloud | Open source SQL/ Apache Spark | |
Load: | Fivetran or Stich | SQL Script, Airbyte Community | |
Dashboard: | Looker, Tableau | Metabase / Superset | |
Observability: | DBT Cloud, Cloud Composer(airflow), New Relic | Airflow + Custom Logic, Grafana | |
Schedule: | Airflow | ||
Data Warehouse:
| BigQuery, Snowflake, Redshift Spectrum | Clickhouse, Druid, Kylin, DuckDB(Serverless) | |
Data Catalog: | Dataplex, Atlan, Castor | DataHub, Open Metadata, Open Data Discovery |
APIs:
APIs are a data source that continues to grow in importance and popularity. A typical organization may have hundreds of external data sources such as SaaS platforms or partner companies.
APIs click to expan...
ETL vs ELT:
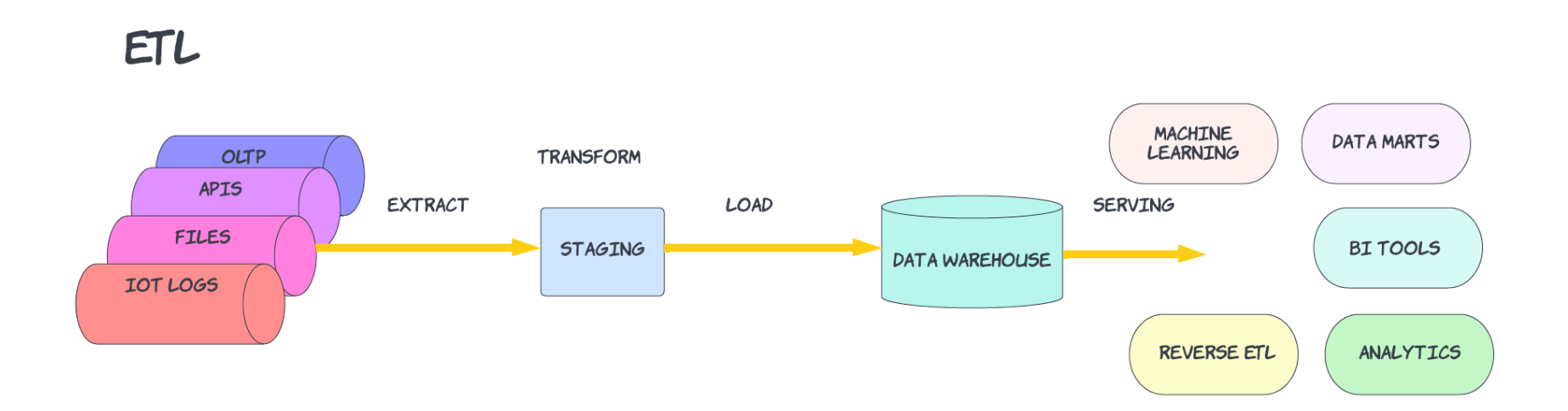
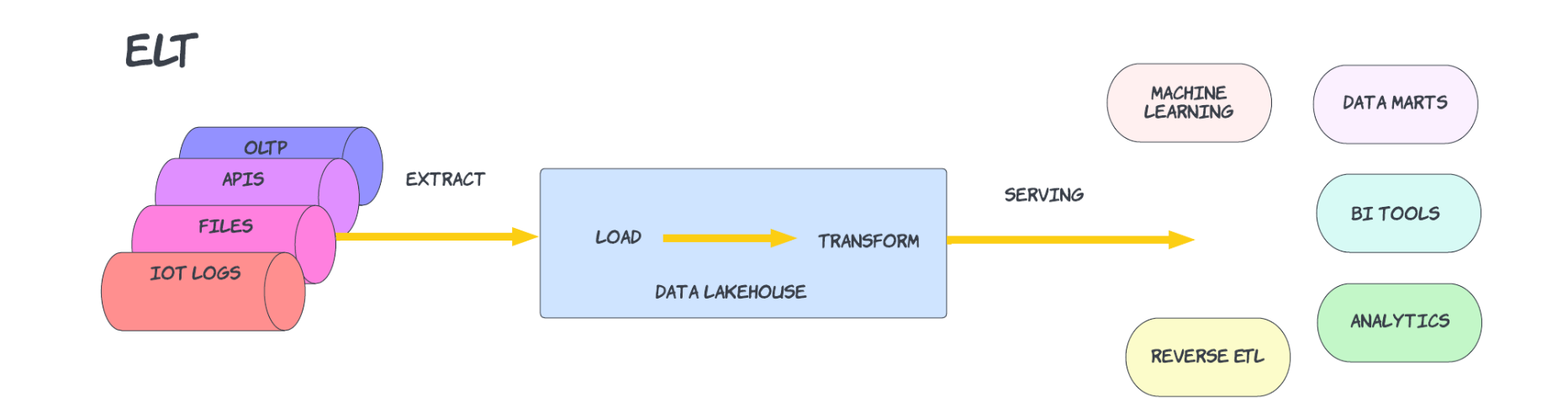
Typical Examples:
ETL = Data is extracted from the source, the raw data is stored in some file storage, transformed via python, spark, scala or other language and loaded into the tables to be used by end user.
ELT: Data is extracted from the source, the raw data is loaded directly into the data warehouse and transformed using SQL into the final table to be used by the end-user. This model has been popularized by dbt.
In a good portion of use cases ELT would be the better fit however if the transformations need to support streaming or more complex needing the power of a spark cluster than ETL would be the better suited.
Simple comparison:
Criteria | Notes | ELT | ETL |
|---|---|---|---|
Running cost | Depending on your data warehouse, performing transformation using k8s tasks or serverless functions(lambdas) can be much cheaper compared to transforming data in your data warehouse. |
| x |
Engineering expertise | Both require a good grasp of distributed systems, coding, maintenance, debugging, and SQL. | x | x |
Development time | Depending on existing tools this may vary. If you have tools like Fivetran or dbt, ELT is a breeze. | x |
|
Transformation capabilities | Programming languages/Frameworks like python, scala, and Spark enable complex transformations (enrich with data from external API, running an ML model, etc). SQL is not as powerful. |
| x |
Latency between data generation and availability of use by end-user | In general, the T of ELT is run as a batch job since SQL does not support streaming transformation. ETL can do batching, micro-batching, or streaming. |
| x |
SAAS tools | ELT allows for faster data feature delivery due to the availability of EL tools (Fivetran, Airbyte, etc). | x |
|
The above table is a great break down from: https://www.startdataengineering.com/post/elt-vs-etl/#3-differences-between-etl--elt
Whats the difference between ETL & ELT?
Cloud ETL Tools:
What qualifies as an ETL tool?
- Facilitate extract, transform, and load processes
- Transform data for quality or visualization
- Audit or record integration data
- Archive data for backup, future reference, or analysis
Tool | Description | Have I seen in action? |
|---|---|---|
dbt is a transformation workflow that lets teams quickly and collaboratively deploy analytics code following software engineering best practices like modularity, portability, CI/CD, and documentation. Now anyone who knows SQL can build production-grade data pipelines. | Yes | |
Fivetran is an automated data integration service | Yes | |
Google’s visual point-and-click interface enabling code-free deployment of ETL/ELT data pipelines | no | |
Hevo Data is an automated data pipeline that helps users migrate, consolidate, and transform data from different sources into their data warehouse | no | |
Keboola enables data engineers, analysts, and engineers to collaborate on analytics and automation as a team, from extraction, transformation, data management, and pipeline orchestration to reverse ET | no |
Storage Beyond the Traditional Database:
Data Warehouse / Data Lakes / Data Lakehouse :
Traditional Database | Data Warehouse | Data Lakes | Data Lakehouse |
|---|---|---|---|
OLTP | OLAP | Catch All Storage for Processing | Catch All Storage for Processing |
Stores Real-time relational structured data | For analyzing archived structured data |
|
|
| Optimized for analytics - OLAP
Data Marts:
| Store for ALL types of data at a lower cost
| More cost effective than traditional data warehouse solutions with…
|
|
|
|
|
Brief overview of popular systems:
A brief overview of the similarities and differences between Snowflake, BigQuery and Databricks.
| |||
|---|---|---|---|
When to use: |
|
|
|
When not to use: | Snowflake may not be suited for real-time or complicated analysis, large datasets, or organizations with really strict security requirements. | BigQuery is not suitable for low-latency, real-time applications, sub-second response times, random reads/writes, data streaming. | Databricks should not be used when the data processing needs are minimal, when the data size is too small, or when there is no need for distributed computing. |
Costs?
Depending on the size and complexity of the data analysis, BigQuery may be more cost-effective than either Snowflake or Databricks. Generally, Snowflake tends to be pricier than Databricks for most applications, however, there are scenarios where Databricks can be more expensive than Snowflake. Ultimately, the cost of each platform depends on the use of features and services each offers.