
Exploring duckDB:
A Lightweight OLAP Database Inspired by PostgreSQL and SQLite

DuckDB the open source in-process, serverless SQL OLAP RDBMS:
Thats a mouthful but descriptive enough for the needs of specific workloads.
"DuckDB is a column-oriented, vectorized RDBMS optimized for analytics workloads."
The database has the simplicity of SQLite but the ability to use more complex analytical SQL queries of PostgreSQL without the hassle of PostgreSQL management but with some limitations. DuckDB uses the PostgreSQL parser and it's a RDBMS as a library which makes it really mobile. It uses vectorize processing makes querying more efficient than, PostgreSQL, MySQL, Pandas, or Numpy.
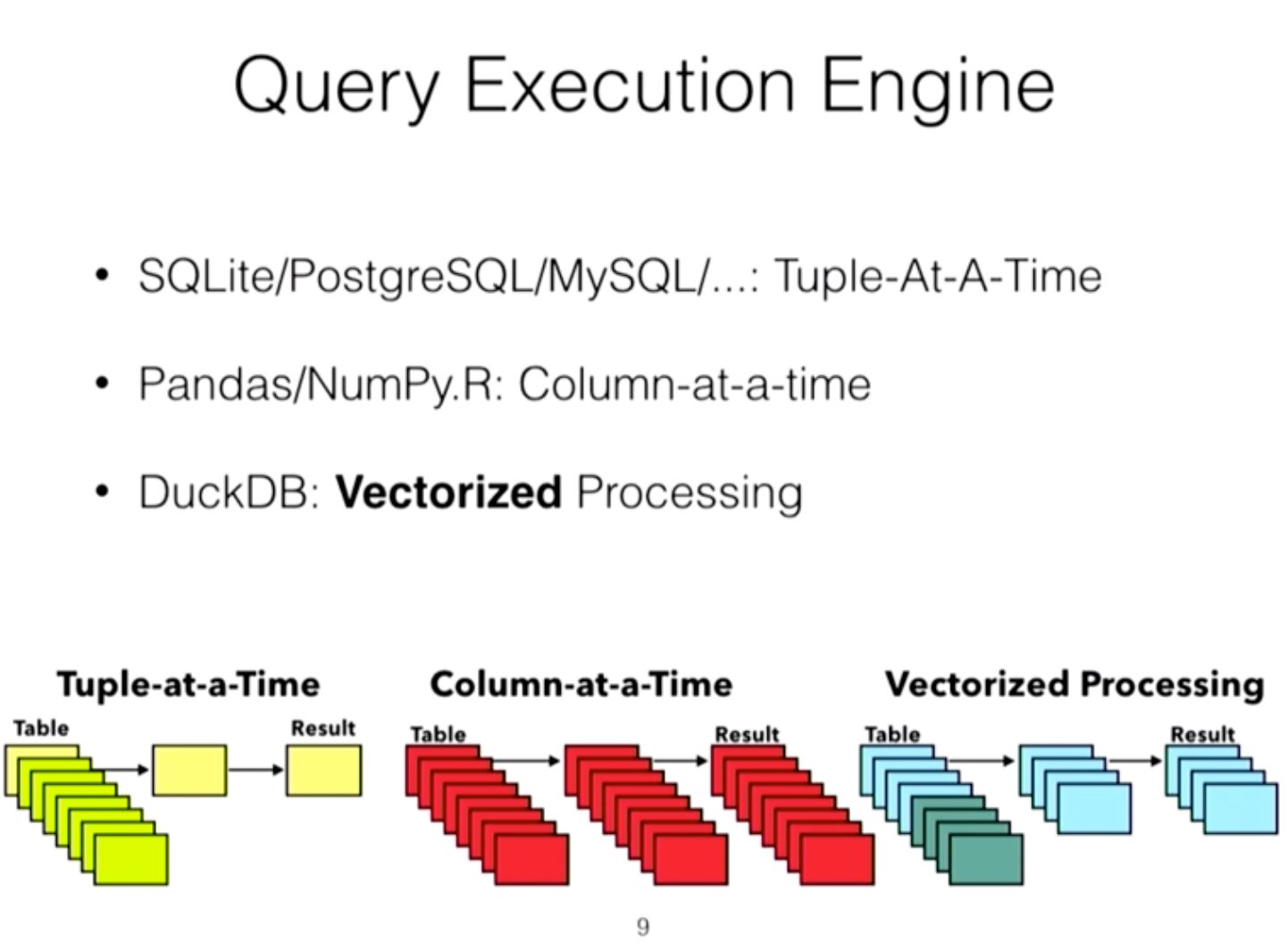
According to them duckDB was 20x-40x faster than the traditional systems because of the Vectorized Processing model.
DuckDB offers a SQL interface and a NoSQL interface, and can be embedded into applications, used as an in-memory database, or run on resource-constrained hardware. It is designed for data warehousing, machine learning, data exploration, time series analysis, and real-time analytics, and supports a wide range of SQL syntax, including window functions, common table expressions, and other SQL constructs. I highlighted warehousing, machine learning, and data exploration as I could immediately see their use cases with only a short time spent with duckDB.
Released 2018 with a MIT License. There is a lot of information on their website the Why DuckDB page.
I found this presentation to be helpful:
https://db.in.tum.de/teaching/ss19/moderndbs/duckdb-tum.pdf
DuckDB is a highly optimized SQL database designed specifically for analytics and machine learning applications. It is designed to be extremely efficient and performant, while maintaining the same expressive SQL syntax as PostgreSQL and other SQL databases. DuckDB also supports a range of query optimization techniques such as query rewrites and columnar storage. This makes it much faster than a DB like PostgreSQL for certain types of analytical queries.
Modern Data Stack in a Box with DuckDB:

As I started playing with duckDB one could quickly see how this could be used for the testing and or the discovery process for analyzing data. A simplistic use case is a data warehouse for your laptop. I will lay down some quick examples using duckDB with Python and the CLI to demonstrate the ease of use and potential.
Docs for install:
Simple installation instructions can be found here Install_duckDB
Quick Example using Python:
Install = pipe install duckdb
Via Python3 Interactive:
>>> import duckdb
>>> con = duckdb.connect(database=':memory:')
>>> con.execute("CREATE TABLE items(item VARCHAR, value DECIMAL(10,2), count INTEGER)")
<duckdb.DuckDBPyConnection object at 0x12224d130>
>>> con.execute("INSERT INTO items VALUES ('jeans', 20.0, 1), ('hammer', 42.2, 2)")
<duckdb.DuckDBPyConnection object at 0x12224d130>
>>> con.execute("SELECT * FROM items")
<duckdb.DuckDBPyConnection object at 0x12224d130>
>>> print(con.fetchall())
[('jeans', Decimal('20.00'), 1), ('hammer', Decimal('42.20'), 2)]
>>> con.execute("SELECT SUM(value) FROM items")
<duckdb.DuckDBPyConnection object at 0x12224d130>
>>> print(con.fetchall())
[(Decimal('62.20'),)]Quick example using the CLI:
Using the CLI and Query CSV file directly from filesystem:
Using the faker module in python I created a CSV file with over 11 Million rows. With a traditional database like MySQL or PostgreSQL, I had to build the table and import the file but before that I had to set configs to allow CSV files from a specific path, restart the database and still had to clean the data before I could import it. With duckDB either through python or the CLI which is a binary file depending on OS it was really simple to start querying data.
To run in Memory ./duckdb
To run and persist to a data file ./duckdb data/my_test.duckdb
Anything you write to the db will persist to disk.
You can query from a direct file on your filesystem in csv or parquet format.
Note: All data is fake
D SELECT count(*) FROM '/bluedev/data/user_data.csv' ;
99% ▕███████████████████████████████████████████████████████████▍▏ ┌──────────────┐
│ count_star() │
│ int64 │
├──────────────┤
│ 11128978 │
└──────────────┘You can query the .csv file like any other database without importing it.
D SELECT * FROM '/bluedev/data/user_data.csv' limit 1 ;
┌──────────────────────┬─────────┬──────────────┬────────────┬─────────────────┬──────────────────────┬───┬─────────────┬──────────┬─────────┬───────┬──────────┬─────────────────────┬─────────┐
│ Email Id │ Prefix │ Name │ Birth Date │ Phone Number │ Additional Email Id │ … │ City │ State │ Country │ Year │ Time │ Link │ Text │
│ varchar │ varchar │ varchar │ date │ varchar │ varchar │ │ varchar │ varchar │ varchar │ int32 │ time │ varchar │ varchar │
├──────────────────────┼─────────┼──────────────┼────────────┼─────────────────┼──────────────────────┼───┼─────────────┼──────────┼─────────┼───────┼──────────┼─────────────────────┼─────────┤
│ Gregory.Buchanan@t… │ Mrs. │ James Miller │ 1998-06-09 │ (0116) 496 0094 │ veronicasmith@exam… │ … │ Sandrashire │ Michigan │ Bermuda │ 2017 │ 07:27:35 │ http://wilson.info/ │ send │
├──────────────────────┴─────────┴──────────────┴────────────┴─────────────────┴──────────────────────┴───┴─────────────┴──────────┴─────────┴───────┴──────────┴─────────────────────┴─────────┤
│ 1 rows 15 columns (13 shown) │
└───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┘We're able to create our own table and import it from the .csv with limited set up.
In this example I am creating a table country_counts while importing based off my query SELECT country, count(country) as count on the .csv file.
D create table country_counts as SELECT country, count(country) as count FROM '/bluedev/data/user_data.csv' group by country;
99% ▕███████████████████████████████████████████████████████████▍▏ Run tables command to show tables.
D .tables
country_countsNow we can query the new table 'country_counts'.
D select * from country_counts limit 5;
┌─────────┬───────┐
│ Country │ count │
│ varchar │ int64 │
├─────────┼───────┤
│ Bermuda │ 45547 │
│ Vietnam │ 45817 │
│ Rwanda │ 45139 │
│ Georgia │ 45595 │
│ Korea │ 91225 │
└─────────┴───────┘Using DuckDB with a Juptyer Notebook:
Let's see if there is jupyter support?
Requirements:
pip install duckdb
pip install jupyterlab # or just jupyter
# Install supporting libraries
pip install jupysql
pip install duckdb-engine
pip install pandas # conda install pandas (in case pip fails)
pip install matplotlibIn jupyter notebook I added the following:
%config SqlMagic.autopandas = True
%config SqlMagic.feedback = False
%config SqlMagic.displaycon = False
Setting up duckdb in memory was as simple as:
%sql duckdb:///:memory:Below is an example reading a parquet file directly on the filesystem with 10 million rows and plotting the SQL results.
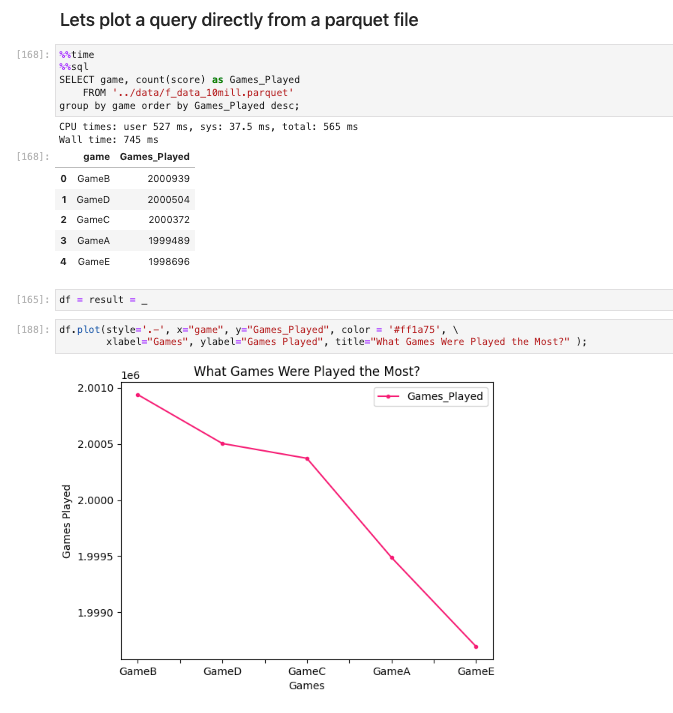
As you can see it scanned 10 million rows in directly from the file in 946ms and it was pretty easy to plot the sql statement results on Jupyter Notebooks.
VS Code also has an extension from "SQLTools" that supports connecting and using duckdb.
So far I see it as a great tool for testing or discovery on datasets without the overhead of setting up a typical RDBMS. Since duckdb is serverless it is mobile, allows options for persisting and easily sharing data. As for using in an enterprise solution? Maybe for processing data that is in that sweet spot of needing more than pandas has to offer and not needing the power of a giant spark cluster. DuckDB will not replace the enterprise data warehouse. This being said I can see it as my go to DW for testing on my local_dev.
I will do more some time down the road. It will not replace an enterprise data warehouse however there can be many more use cases for duckDB and I look forward in playing some more.
Conclusion:
With a quick look at DuckDB I feel this will be a great tool to have in your toolbox, due to its simple usage and serverless architecture. I have only just scratched the surface of its features. It has the ability to connect to other databases while utilizing its own query engine. DuckDB also has the capability to run complex queries and a wide range of aggregation functions which you can't find in some of the traditional open source RDMS. However, if you are familiar with PostgreSQL, then you will find DuckDB's SQL syntax easy to use.